Artificial intelligence is getting its teeth into lip reading. A project by Google’s DeepMind and the University of Oxford applied deep learning to a huge data set of BBC programmes to create a lip-reading system that leaves professionals in the dust.
 The AI system was trained using some 5000 hours from six different TV programmes, including Newsnight, BBC Breakfast and Question Time. In total, the videos contained 118,000 sentences.
The AI system was trained using some 5000 hours from six different TV programmes, including Newsnight, BBC Breakfast and Question Time. In total, the videos contained 118,000 sentences.
First the University of Oxford and DeepMind researchers trained the AI on shows that aired between January 2010 and December 2015. Then they tested its performance on programmes broadcast between March and September 2016. By only looking at each speaker’s lips, the system accurately deciphered entire phrases, with examples including “We know there will be hundreds of journalists here as well” and “According to the latest figures from the Office of National Statistics”.
Here is a clip from the database without subtitles:

And here’s the same clip with subtitles provided by the AI system:
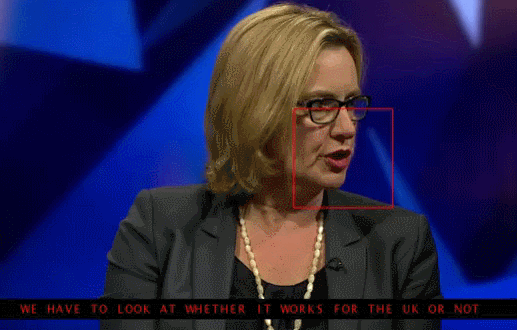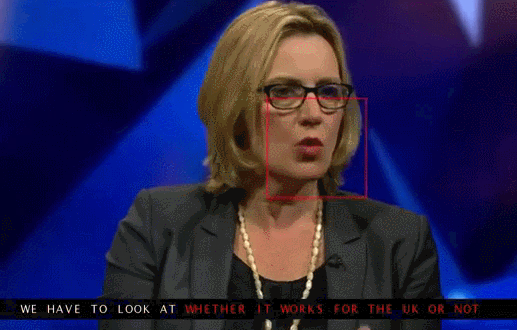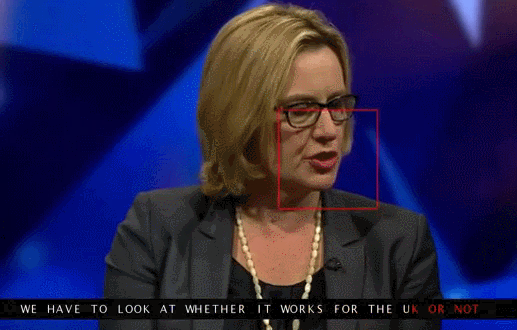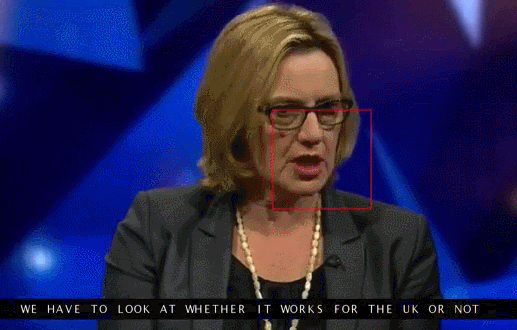
AI shows the way
The AI vastly outperformed a professional lip-reader who attempted to decipher 200 randomly selected clips from the data set.
The professional annotated just 12.4 per cent of words without any error. But the AI annotated 46.8 per cent of all words in the March to September data set without any error. And many of its mistakes were small slips, like missing an ‘s’ at the end of a word. With these results, the system also outperforms all other automatic lip-reading systems.
“It’s a big step for developing fully automatic lip-reading systems,” says Ziheng Zhou at the University of Oulu in Finland. “Without that huge data set, it’s very difficult for us to verify new technologies like deep learning.”
Two weeks ago, a similar deep learning system called LipNet – also developed at the University of Oxford – outperformed humans on a lip-reading data set known as GRID. But where GRID only contains a vocabulary of 51 unique words, the BBC data set contains nearly 17,500 unique words, making it a much bigger challenge.
In addition, the grammar in the BBC data set comes from a wide diversity of real human speech, whereas the grammar in GRID’s 33,000 sentences follows the same pattern and so is far easier to predict.
The DeepMind and Oxford group says it will release its BBC data set as a training resource. Yannis Assael, who is working on LipNet, says he is looking forward to using it.
Lining up the lips
To make the BBC data set suitable for automatic lip reading in the study, video clips had to be prepared using machine learning. The problem was that the audio and video streams were sometimes out of sync by almost a second, which would have made it impossible for the AI to learn associations between the words said and the way the speaker moved their lips.
But by assuming that most of the video was correctly synced to its audio, a computer system was taught the correct links between sounds and mouth shapes. Using this information, the system figured out how much the feeds were out of sync when they didn’t match up, and realigned them. It then automatically processed all 5000 hours of the video and audio ready for the lip-reading challenge – a task that would have been onerous by hand.
The question now is how to use AI’s new lip-reading capabilities. We probably don’t need to fear computer systems eavesdropping on our conversations by reading our lips because long-range microphones are better for spying in most situations.
Instead, Zhou thinks lip-reading AIs are most likely to be used in consumer devices to help them figure out what we are trying to say. “We believe that machine lip readers have enormous practical potential, with applications in improved hearing aids, silent dictation in public spaces (Siri will never have to hear your voice again) and speech recognition in noisy environments,” says Assael.













